
11. November 2022
Das Fachgebiet der Digitalen Geisteswissenschaften oder Digital Humanities umfasst laut Wikipedia „die systematische Nutzung computergestützter Verfahren und digitaler Ressourcen in den Geistes- und Kulturwissenschaften sowie die Reflexion über deren Anwendung“. Doch welche konkreten digitalen Werkzeuge sind in den Geisteswissenschaften besonders relevant? Da auch an der HAB ein Teil des Personals auf diesem Gebiet arbeitet, schien es uns (Michael Wenzel und Martin de la Iglesia vom DFG-geförderten Projekt “Kommentierte digitale Edition der Reise- und Sammlungsbeschreibungen Philipp Hainhofers (1578-1647)“, sowie Timo Steyer von der UB Braunschweig) eine gute Idee, Expert*innen nach Wolfenbüttel einzuladen, damit diese jeweils eine Software-Anwendung vorstellen. So kam es zu dem Workshop „Von Daten zu Wissen – Workshop zu ausgewählten DH-Tools“ am 29. und 30.9.2022, an dem über 20 Interessierte aus ganz Deutschland teilnahmen.
OpenRefine, präsentiert von Hanna Varachkina (Göttingen), ist ein Werkzeug zur Bearbeitung tabellarischer Daten. Da man in den Digital Humanities ständig mit Daten zu tun hat, die entweder bereits in Tabellenform vorliegen oder sich leicht in eine solche bringen lassen, ist OpenRefine vielseitig einsetzbar. Es handelt sich um eine auf dem lokalen Rechner laufende Anwendung, welche über ein Interface im Web-Browser bedient wird. Durch OpenRefine lassen sich Daten analysieren, sortieren, bereinigen, vereinheitlichen, in andere Formate überführen, und sogar durch externe Datenquellen anreichern. Mögliche Use Cases könnten beispielsweise sein, alte Datenbanken zu migrieren, Personen mit der Gemeinsamen Normdatei zu verknüpfen um sie – unabhängig von ihrem Namen – eindeutig zu identifizieren, oder die Häufigkeit von Schlagwörtern einer Textsammlung darzustellen, um einen Überblick über die behandelten Themen zu erhalten.
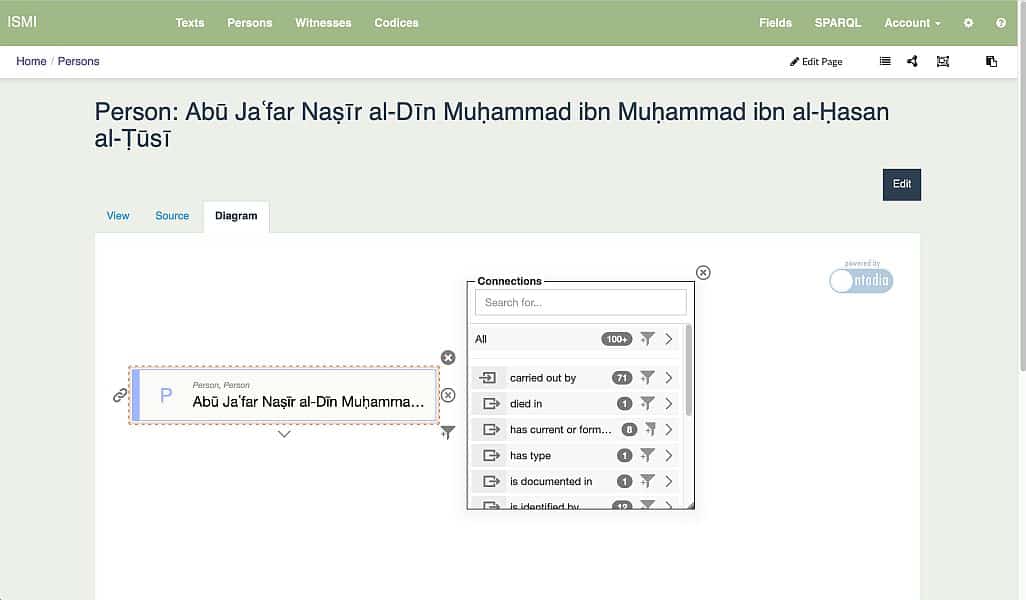
Robert Casties (Berlin) stellte ResearchSpace vor, ein Datenpflege-Frontend für RDF-Datenbanken. RDF (Resource Description Format) ist gewissermaßen die Lingua franca des Semantic Web und für dessen Bausteine, Linked Data. ResearchSpace bietet eine visuelle, anschauliche Möglichkeit der Datenmodellierung und der Verwaltung solcher Wissensgraphen. So können beispielsweise bibliographische Metadaten aus Handschriftensammlungen untereinander und mit externen Daten in Beziehung gesetzt werden, und das auf semantisch interoperable, also maschinell interpretierbare Art und Weise. Die mit ResearchSpace verwalteten Daten können in Webseiten eingespeist werden, wo sie von Nutzer*innen abgerufen und durchsucht werden können. Ein Beispiel für einen mittels ResearchSpace verwalteten Datenbestand wäre ISMI (Islamic Scientific Manuscripts Initiative).
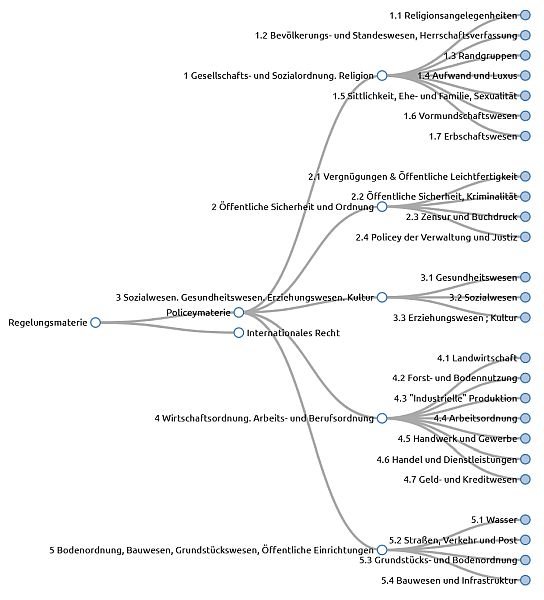
Bei der Datenmodellierung wird man geradezu zwangsläufig feststellen, dass die Eigenschaften der Daten, die man beschreiben möchte, nicht immer durch bereits bestehende Klassifikationsschemata – man spricht auch von kontrollierten Vokabularen, Taxonomien, Thesauri und Ontologien, auch wenn es strenggenommen Unterschiede gibt – abgedeckt werden. Um dennoch interoperable Daten anbieten zu können, empfiehlt sich in solchen Fällen die Erstellung eines eigenen Klassifikationsschemas. Andreas Wagner (Frankfurt) demonstrierte einen Workflow, um ein solches Schema zu konzipieren, im Format SKOS (Simple Knowledge Organization System) zu modellieren, mittels SkoHub und GitHub Pages zu veröffentlichen und über einen Reconciliation Service auszuliefern, was beispielsweise die Einbindung der Klassifikation in OpenRefine ermöglicht. Ein auf diese Weise erstelltes Klassifikationsschema ist leicht nachnutzbar, was auch die Interoperabilität der Daten begünstigt, auf die das Schema angewendet wird.
Der Umgang mit Texten und mittlerweile auch mit zweidimensionalen Bildern ist für Digital Humanists alltäglich geworden. Doch was ist mit mehransichtigen Objekten, die durch ein oder selbst mehrere Bilder nicht adäquat repräsentiert werden können? Wie Astrid Schmölzer (Bamberg) anhand des Tools Agisoft Metashape zeigte, ist es gar nicht so schwer, mit Fotos aus verschiedenen Blickwinkeln ein 3D-Modell eines beliebigen Objekts zu erzeugen. Damit dieses Photogrammetrieverfahren (auch SfM – Structure from Motion – genannt) funktioniert, sind neben der kostenpflichtigen Software ein einigermaßen leistungsstarker Rechner und eine Vielzahl von Photographien des Objekts notwendig, welche aber auch mit einer gewöhnlichen Handykamera aufgenommen werden können. Die einzelnen Bilder werden dabei automatisch zu einem dreidimensionalen Objekt zusammengesetzt, welches sich beliebig drehen und von allen Seiten betrachten lässt. Die Resultate lassen sich in allen gängigen Formaten exportieren, so dass sie z.B. in Webseiten eingebunden werden können.
Warum sollte man als Geisteswissenschaftler*in überhaupt digitale Tools nutzen? In seinem Eröffnungsvortrag hatte Jan Horstmann (Münster) diese Frage u.a. damit beantwortet, dass auf diese Weise die Geisteswissenschaften (Humanities) mit den „exakten“ Wissenschaften (Sciences) Synergien eingehen und sich gegenseitig ergänzen könnten, so dass sich „neue Perspektiven auf ‚alte‘ Fragen“ ergäben. In dieser Hinsicht konnte der Workshop „Von Daten zu Wissen“ so manche Anregung geben.
PURL: http://diglib.hab.de/?link=126
Abbildung oben: 3D-Modell eines attischen Votivreliefs aus dem Museo d'Antichità, Triest. Erstellt von Astrid Schmölzer mittels Agisoft Metashape.
Der Autor








