
11 November 2022
The digital humanities, according to Wikipedia, is a field that includes ‘the systematic use of digital resources in the humanities, as well the analysis of their application’. But what digital tools are specifically relevant to the humanities? As there are a number of staff at the HAB who work in this field, we – that is, Michael Wenzel and Martin de la Iglesia from the project ‘Annotated digital edition of Reiseberichte und Sammlungsbeschreibungen by Philipp Hainhofer (1578–1647)’, which is funded by the Deutsche Forschungsgemeinschaft (German Research Foundation, DFG), along with Timo Steyer from the UB Braunschweig (Braunschweig University Library) – thought it a good idea to invite some experts to Wolfenbüttel to given an introduction to these apps. This was the inspiration for ‘From data to knowledge: A workshop on selected DH tools’. The workshop was held on 29 and 30 September 2022 and attended by more than 20 participants from all over Germany.
OpenRefine, presented by Hanna Varachkina (Göttingen), is a tool for working with spreadsheets. Since digital humanities consistently involves working with data that is either already available in tabular form or can easily be converted into such, OpenRefine has a wide range of potential uses. It is an application that runs on a local computer and is operated via a browser interface. OpenRefine can be used to analyse, sort, clean up and standardise data, convert it to other formats and even enrich it through external data sources. Possible use cases include migrating old databases, linking individuals to the Gemeinsame Normdatei (Integrated Authority File or GND) so that they can be clearly identified – independently of their name – or displaying the frequency of keywords in a text collection to afford an overview of the topics addressed in it.
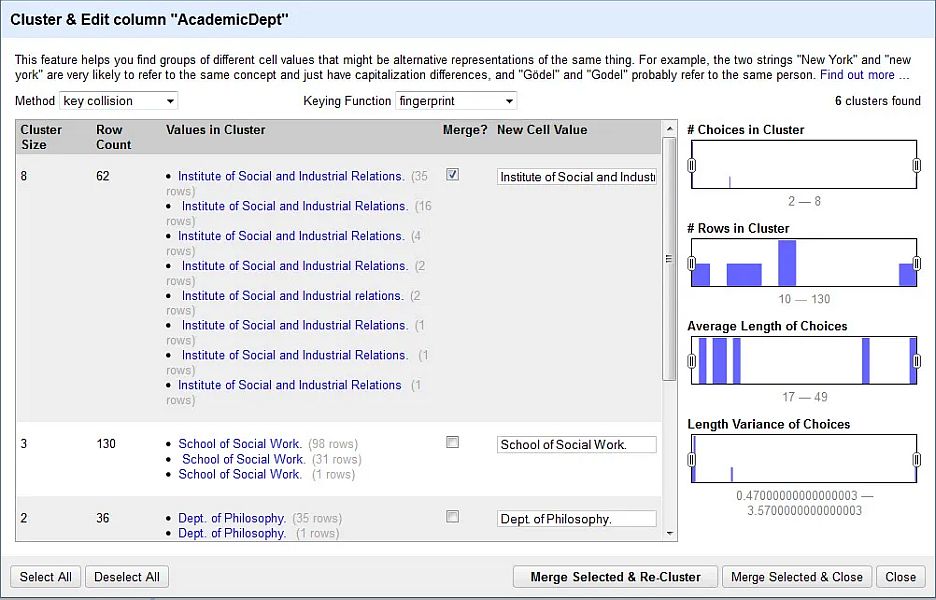
Robert Casties (Berlin) introduced ResearchSpace, a data maintenance front end for RDF databases – RDF (Resource Description Format) could be described as the lingua franca of the Semantic Web – and for the building blocks of RDF, Linked Data. ResearchSpace provides a visually descriptive way of modelling data and managing knowledge graphs. This means that bibliographic metadata from manuscript collections can be collated internally as well with external data in a way that is semantically interoperable, i.e. that computers can interpret. The data managed by ResearchSpace can be uploaded to websites, where it is accessible to users as a searchable resource. One example of a dataset managed by ResearchSpace is ISMI (Islamic Scientific Manuscripts Initiative).
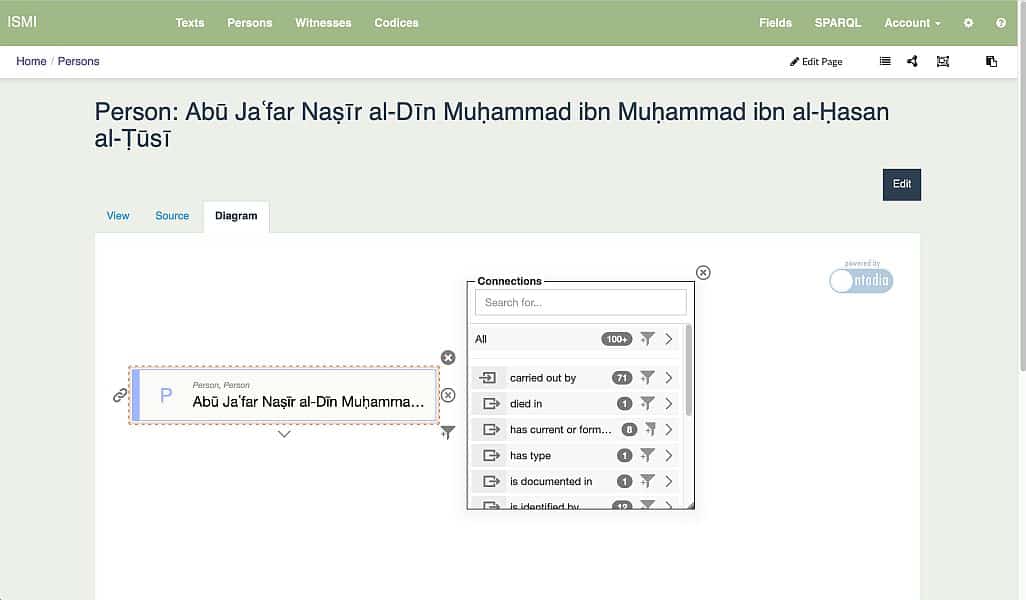
In data modelling, almost inevitably one will find that the properties of the data one wants to describe are not covered by existing classification schemes – so-called controlled vocabularies, taxonomies, thesauri and ontologies, even if, strictly speaking, there are differences between these. This means that in order to be able to provide interoperable data in such cases, it is necessary to create a customised classification scheme. Andreas Wagner (Frankfurt) demonstrated a workflow to show how such a scheme might be designed, modelled in SKOS (Simple Knowledge Organization System), published using SkoHub and GitHub pages and delivered via a reconciliation service, which allows the classification to be integrated into an app like OpenRefine. A classification scheme created in this way is easily reusable, which also promotes the interoperability of the data to which the scheme is applied.
Dealing with texts and even two-dimensional images is now a commonplace activity for digital humanists. But what about multi-view objects that cannot be adequately represented in one or even several images? As Astrid Schmölzer (Bamberg) demonstrated using the Agisoft Metashape tool, it is not overly difficult to create a 3D model of a given object using photographs taken from different angles. All that is needed to use this photogrammetric technique (also known as SfM – Structure from Motion) is – besides the proprietary software – a reasonably powerful computer and plenty of photographs of the object, which can also be taken with a regular smartphone camera. The individual images are automatically assembled into a three-dimensional object that can be rotated as desired and viewed from all sides. The results can be exported in all the usual formats for integration into websites, for example.
But why should humanities scholars use these digital tools in the first place? In his opening talk, Jan Horstmann (Münster) explained that they will allow the humanities to synergise with the ‘hard’ sciences so that they can complement one another, allowing ‘new perspectives on “old” questions’ to emerge. In this respect, the ‘From Data to Knowledge’ workshop certainly provided plenty of inspiration.
PURL: http://diglib.hab.de/?link=126
Image (top): 3D model of an Attic votive relief from the Museo d’Antichità, Trieste. Created by Astrid Schmölzer using Agisoft Metashape.
The author








